FPCS: Feature Preserving Compensated Sampling of Streaming Time Series Data
Hongyan Li - China Nanhu Academy of Electronics and Information Technology(CNAEIT), JiaXing, China
Bo Yang - China Nanhu Academy of Electronics and Information Technology(CNAEIT), JiaXing, China
Yansong Chua - China Nanhu Academy of Electronics and Information Technology, Jiaxing, China
Room: Palma Ceia I
2024-10-16T12:30:00ZGMT-0600Change your timezone on the schedule page
2024-10-16T12:30:00Z
Fast forward
Full Video
Keywords
Data visualization, Massive, Streaming, Time series, Line charts, Sampling, Feature, Compensating
Abstract
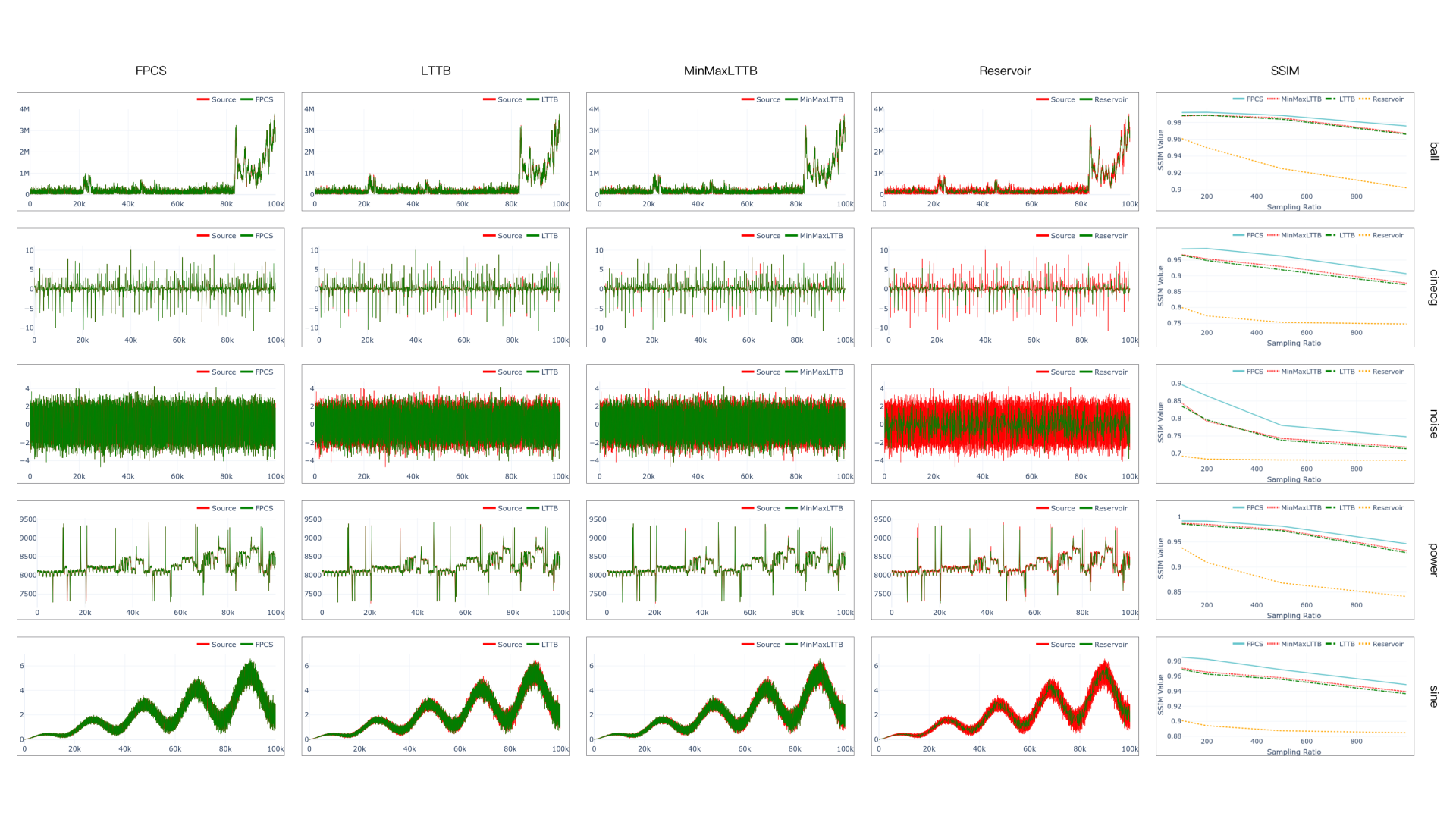
Data visualization aids in making data analysis more intuitive and in-depth, with widespread applications in fields such as biology, finance, and medicine. For massive and continuously growing streaming time series data, these data are typically visualized in the form of line charts, but the data transmission puts significant pressure on the network, leading to visualization lag or even failure to render completely. This paper proposes a universal sampling algorithm FPCS, which retains feature points from continuously received streaming time series data, compensates for the frequent fluctuating feature points, and aims to achieve efficient visualization. This algorithm bridges the gap in sampling for streaming time series data. The algorithm has several advantages: (1) It optimizes the sampling results by compensating for fewer feature points, retaining the visualization features of the original data very well, ensuring high-quality sampled data; (2) The execution time is the shortest compared to similar existing algorithms; (3) It has an almost negligible space overhead; (4) The data sampling process does not depend on the overall data; (5) This algorithm can be applied to infinite streaming data and finite static data.